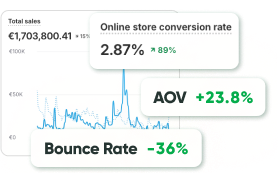
For many marketing teams, A/B testing is considered the foundation of conversion optimization. The logic is simple: try two versions of a page, measure which one performs better, and implement the winner. Over time, this should create steady growth.
The reality is less straightforward. Industry research shows that only about 14 percent of A/B tests produce statistically significant wins. A large-scale analysis of more than 28,000 experiments revealed that just 20 percent reach the 95 percent confidence threshold. In other words, most tests will not deliver a clean uplift.
At first glance this seems discouraging. Why run experiments that often fail to produce revenue gains? The answer is that A/B testing is not only about finding winners. It is about learning. Every result contains insight, whether the outcome is positive, flat, or negative.
Rethinking What Failure Means
The language of “winning” and “losing” tests has created the wrong expectations. A variation that does not outperform the control is often dismissed as a waste of time. This perspective ignores the true purpose of experimentation.
In science, some of the most famous breakthroughs came from experiments that disproved the original hypothesis. These results forced researchers to rethink assumptions and led to stronger theories. A/B testing follows the same principle. A test that shows no change, or even a decline, is still useful.
- Flat results highlight where assumptions about user behavior were wrong or where effects are too small to matter.
- Negative results protect companies from rolling out harmful changes to the entire audience.
- Surprising results reveal hidden patterns and create new questions for further testing.
The only true failure is running a test and refusing to learn from the outcome.
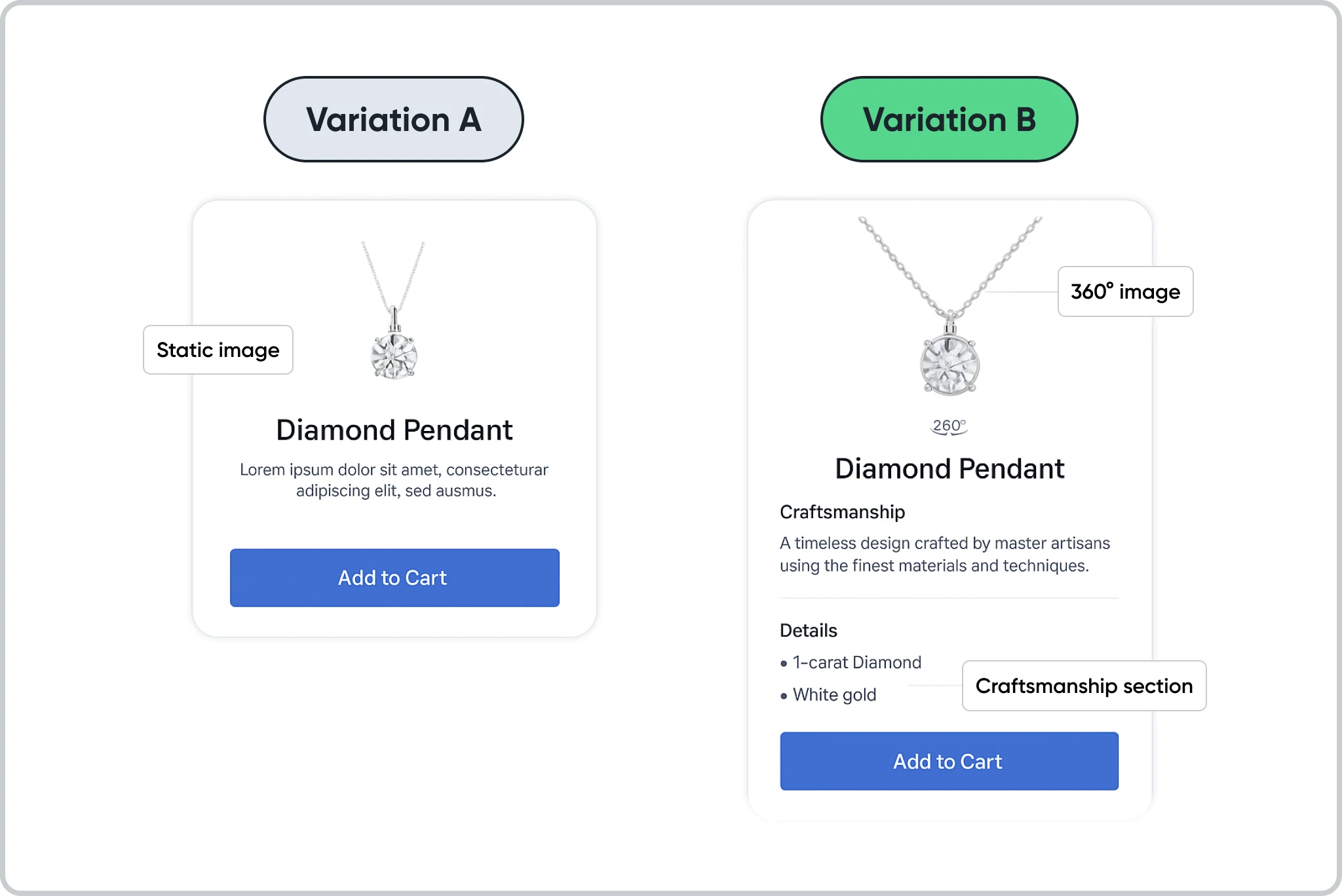
Why Most A/B Tests Appear to Fail
There are several recurring reasons experiments do not show the results teams hope for.
Limited traffic and small samples
Tests often run on too little data. To detect a 10 percent lift on a 2 percent baseline conversion rate, you need more than 8,000 users per variation. Small samples produce random fluctuations that look meaningful but are not reliable.
Stopping early
Teams are tempted to end tests when one variation looks like it is winning after a few days. In reality, behavior varies by day of the week and by traffic cycle. A result that looks strong early often fades when more data is collected.
Testing superficial changes
Changing button colors or swapping a headline is unlikely to solve deep conversion problems. If users abandon checkout because of hidden costs or confusing flows, cosmetic changes will not address the real friction.
Wrong performance metrics
Click-through rate or engagement might increase while revenue per visitor declines. Optimizing for vanity metrics leads to misleading conclusions.
Ignoring segments
Aggregated results hide variation across audiences. A test may look flat overall but show meaningful differences for mobile users compared to desktop, or for new visitors compared to returning customers.
Lack of documentation
Many teams do not log their experiments properly. This leads to repeated tests, forgotten learnings, and lost context when staff changes.
Real Cases
Some of the clearest business insights emerge from experiments that do not deliver uplift.
- Zalora — Highlighting Free Returns and Delivery
Zalora, a leading Asian fashion retailer, optimized their product pages to emphasize free return and delivery policies. This seemingly small adjustment generated a 12.3% increase in checkout conversions, proving that messaging clarity often matters more than flashy design. - Ubisoft — Simplifying the Purchase Page
Ubisoft tested a simplified “Buy Now” page with less scrolling and a cleaner design. The streamlined approach increased conversions from 38% to 50% and generated a 12% lift in leads, showing how reducing friction outperforms adding more options. (vwo.com) - PayU — Removing the Email Field
The fintech company PayU experimented with shorter checkout forms by removing the email field and leaving only the phone number. The simplified process delivered a 5.8% increase in conversions, a small but meaningful improvement for high-volume transactions. - ShopClues — Rethinking Homepage Categories
Indian eCommerce platform ShopClues moved a key category into a more visible position on the homepage, renaming it from “Wholesale” to “Super Saver Bazaar.” The change increased interaction with categories and boosted visit-to-order conversions by 26%.
These cases demonstrate that tests either save wasted spend, uncover opportunities for targeted improvements, or confirm whether bold strategies are worth pursuing.
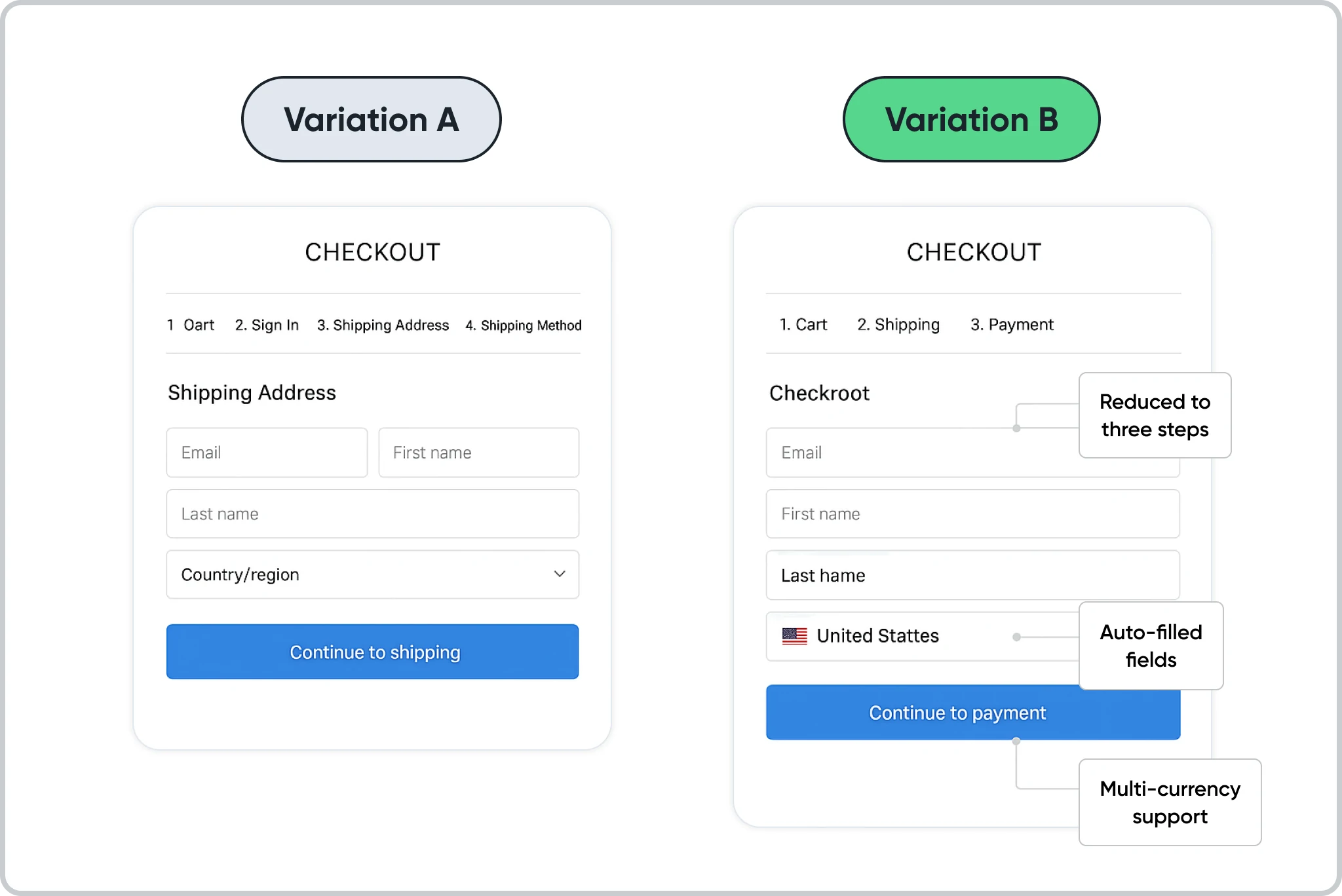
Building a Scientific Approach to A/B Testing
Companies that learn the most from testing treat it as a structured research process rather than a search for quick wins.
Step 1. Start with a meaningful question
An example might be “Will offering a discount to new users increase revenue per user?” Questions like this are more valuable than “Will a red button outperform a green button?”
Step 2. Form a clear hypothesis
Ground your guess in existing knowledge. If past data shows new customers are highly price sensitive, hypothesize that lowering the average cart value with a discount will lift revenue.
Step 3. Define independent and dependent variables
Independent variable: the discount percentage. Dependent variable: revenue per user. Control: no discount. This ensures the experiment produces actionable conclusions.
Step 4. Plan segmentation in advance
Traffic from search ads may behave differently than traffic from organic or referral. Segmenting results gives a more accurate view of user behavior.
Step 5. Choose the right metrics
Revenue, conversion rate, and cart abandonment are business-critical. Secondary metrics like CTR should be treated with caution.
Step 6. Run long enough to be valid
Allow tests to run at least 30 days or until the required sample size is reached. Short tests rarely produce reliable results.
Step 7. Analyze with curiosity
Instead of asking whether a variation won, ask what the test revealed about your audience. Did certain users behave differently? Did an unexpected variable affect the outcome?
Why Negative and Flat Tests Drive Growth
Flat and negative outcomes are valuable because they push teams to reassess assumptions. They reveal that not all tactics work equally across segments. They prevent large-scale rollouts of harmful ideas. They also highlight areas where future tests can be refined.
Over time, this disciplined approach compounds. You avoid wasting money on ineffective tactics, discover strategies that resonate with key audiences, and build a deeper understanding of your customer base.
Final Thoughts
It is easy to feel discouraged by the statistics. Most A/B tests will not produce clean wins. But that does not mean testing is broken. It means experimentation works the way science does: by disproving assumptions and gradually building a stronger model of reality.
When you treat every result as insight, not judgment, A/B testing becomes one of the most powerful tools for long-term optimization. Positive outcomes grow revenue directly. Negative and flat outcomes sharpen strategy, refine targeting, and save resources. Together, they create a cycle of continuous learning.
At GoMage, we help eCommerce brands adopt this exact mindset. By combining CRO expertise, UX/UI design, and data driven experimentation, we empower our clients to turn every test, whether win, flat or negative, into a stepping stone for growth.
Instead of chasing quick wins, we partner with businesses to build sustainable optimization strategies that scale globally and reflect the true value of their brand.
FAQ
A/B testing is pretty straightforward, you make two versions of something (could be a webpage, an email, whatever) and show each version to different people. Then you see which one works better. We’ve been doing this for years and it’s honestly the only reliable way to know if your changes actually help your business or just make things worse.
This happens to everyone starting out. Usually it’s because you’re testing stuff that doesn’t really matter to your customers. Like changing a button from blue to green, who cares? Or you don’t have enough traffic, or you panic and stop the test after three days when you see bad results.
Two weeks minimum, but honestly it depends. If you’ve got tons of traffic, maybe less. If you’re like most small businesses, probably longer. Our team usually waits until we get around 1000 people taking the action we are measuring (like buying something or signing up). Otherwise the numbers are just too jumpy to trust.
First off, have a real reason for what you’re testing. “I think red converts better” isn’t good enough. Look at your data, talk to customers, find actual problems. Test big changes, not tiny tweaks.
Start with your headline/ if people don’t understand what you’re offering in 3 seconds, you’re screwed. Then look at your main button. Is it obvious what happens when someone clicks it? After that, check your forms. I can’t tell you how many times I’ve seen conversion rates jump just by removing unnecessary form fields.
Google Analytics is your friend here, set up goal funnels and see where people bail out. Hotjar or similar tools show you heat maps of where people actually click (spoiler: probably not where you think). But the real gold is watching recordings of real users trying to use your site. It’s painful but eye-opening.
It happens all the time. Maybe your change wasn’t big enough, or maybe what you thought was a problem actually isn’t. Take notes about what you learned and move on to testing something else. Sometimes you need to make bigger, scarier changes to see any movement in your numbers.
Revenue per visitor matters more than conversion rate sometimes. We’ve seen tests where fewer people converted but they spent way more money. Keep an eye on bounce rate too – if your “winning” version scares people away, that’s not really a win. Also check if the results are consistent across different types of visitors.
Make it a habit, not a one-time project. Keep a running list of things to test based on customer complaints, support tickets, or weird patterns you notice in your data. Document everything, even the tests that don’t work, future you will thank you. So, remember, this stuff takes time. Don’t expect overnight miracles.